PS:对于分布式网络环境或者有大量任务的应用,Gearman(Client -> Job Server -> Worker)的通信方式,为开发者搭建分布式负载均衡架构,实现高效稳定的负载均衡处理能力提供了有利的保障。。
简单部署结构-单一Job Server模式

Gearman不但可以做为任务分发,还可以为应用提供负载均衡。开发者既可以在一台多核心单cpu服务器上启动与核心数量相同的worker实例,也可以水平扩展worker实例放在多cpu多核心的服务器上执行。比如,应用视频转换程序,不希望web服务器来处理视频格式转换,这时,可以在专用转码服务器上进行任务分发,在上面加载worker处理视频格式,对外的web服务器就不会被视频转换过程影响。而且扩展方便,加一台服务器到任务调度中心,注册成worker即可,这时job server会在请求到来的时候,将请求发送给空闲的worker。
Tip:client和worker的通信内容的格式:string,int,json,xml.
Gearman 不进行所交换数据的任何转换或操作。对于这里使用的简单字符串和整数没有问题,但是不能共享 PHP 中的数组值并期望能在 Java 语言中被理解。对于这种类型的交互,可以使用很多结构化数据标准中的一种,比如 JavaScript Object Notation (JSON) 或 XML。另外,如果您在处理来自数据库的信息,只要共享 ID 或者找到需要处理的数据时要用到的信息即可,或者使用 memcached 这样的透明方法(尽管可能仍然需要 JSON 或等价物)。
典型部署结构-多job server模式,消除单点困扰

Job Server 可以开启多个实例,组成HA架构,这样在其中一个Job Server发生故障的时候,client和worker会自动 Failover 到其他的Job Server机器上。
从上图可以看出,gearman支持的特性:
1.高可用
启动两个job server,他们是独立的服务进程,有各自的内存队列。当一个job server进程出现故障,另一个job server可以正常调度。(worker api与client api可以完成job server故障的切换)。在任何时候我们可以关闭某个worker,即使那个worker正在处理工作任务(Gearman不会让正在被执行的job丢失的,由于worker在工作时与Job server是长连接,所以一旦worker发生异常,Job server能够迅速感知并重新派发这个异常worker刚才正在执行的工作)
2.负载均衡(附gearman协议会详细解释)
job server并不主动分派工作任务,而是由worker从空闲状态唤醒之后到job server主动抓取工作任务。
3.可扩展
松耦合的接口和无状态的job,只需要启动一个worker,注册到Job server集群即可。新加入的worker不会对现有系统有任何的影响。
4.分布式
gearman是分布式的任务分发框架,worker与job server,client与job server通信基于tcp的socket连接。
5.队列机制
gearman内置内存队列,默认情况队列最大容量为300W,可以配置最大支持2^32-1,即4 294 967 295。
6.高性能
作为Gearman的核心,Job server的是用C/C++实现的,由于只是做简单的任务派发,因此系统的瓶颈不会出在Job server上。
持久化部署结构-memcached持久化多job server模式
关于持久化
持久化队列是在0.6版本中新添的一项功能,允许将队列存放在drizzle或mysql中。0.7版本允许将队列存放在memcached。0.9版本可以将队列存放在sqlite3或postgresql。 在gearman job服务器内部,所有的job队列都是存放在内存中的,这就意味着一旦服务器重启或崩溃,未执行的job将会丢失而不会被worker服务器执行。持久化队列将后台作业存放在一个外部持久的队列中。持久化队列只对后台jobs有效,因为前台jobs依附于客户端。如果job服务器挡掉了,客户端会检测到,将会从其他地方重新启动这个前台job或者返回错误。而后台jobs没有依附于客户端,如果要想让它运行则需要提交。
对于队列持久化的问题,是一个值得考虑的问题。持久化必然影响高性能。gearman支持后台工作任务的持久化,支持drizzle、mysql、memcached的持久化。对于client提交的background job,Job server除了将其放在内存队列中进行派发之外,还会将其持久化到外部的持久化队列中。一旦Job server发生问题重启,外部持久化队列中的background job将会被恢复到内存中,参与Job server新的派发当中。这保证了已提交未执行的background job不会由于Job server发生异常而丢失。并且我测试发现如果开启了持久化,那么后台工作任务会先将工作任务写到持久化介质,然后在入内存队列,再执行。非后台工作任务,由于client与job server是保持长连接的状态,如果工作任务执行异常,client可以灵活处理,所以无须持久化。
上例典型部署结构带来的问题思考
从典型部署结构看出,两个Job server之间是没有连接的。也就是Job server间是不共享background job的。如果通过让两个Job server指向同一个持久化队列,可以让两个Job serer互相备份。但实际上,这样是行不通的。因为Job server只有在启动时才会将持久化队列中的background job转入到内存队列。也就是说,Job server1如果宕机且永远不启动,Job server2一直正常运行,那么Job server1宕机前被提交到Job server1的未被执行的background job将永远都呆在持久化队列中,得不到执行。另外如果多个job server实例指向同一个持久化队列,同时重启多个job server实例会导致持久队列中的工作任务被多次载入,从而导致消息重复处理。
优化后的部署结构
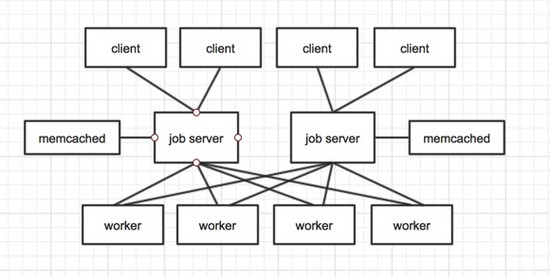
采用memcached做后台工作任务的准持久化队列,最好memcached和job server在内网的不同机器。两个机器的两个服务同时挂掉的可能性比较小,同时也保证了高性能。而且memcached应该为两个相互独立实例,防止其上述的gearman框架中的问题。我们可以做一个监控脚本,如果某个job server异常退出,可以重启,也最大化的保证了job server的高可用。
关于gearman的分布式任务处理架构的认识总结:
1. 其实每一个任务处理的时间并没有降低,相反会稍稍有所增加,主要是数据在网络上传输的一些时间。
2. 前端Client(通常是web服务器)的负载降低了,但是转移到了后端Worker上。计算不可能凭空消失,只不过从一台机器转移到了另外一台机器。
3. 同步阻塞方式的任务,前端Client(通常是Web服务器)等待的时间与后端Worker的数量与当前任务数有关。如果当前任务数量<=Worker数量,前端Client等待的时间约等于一个任务处理的时间。但是当前任务数>=Worker数量时,就会出现某些Client等待的情况,某个Client只有等到一个空闲的Worker,才会将任务交给它进行处理。
设想一下,在任务数<=Worker数量的时候,使用gearman是可以提高响应时间的。如果采用单机话,N个任务还是在一台机器上运行,每个任务需要
现在有N个任务(Client),M个Worker,每个任务执行时间为t。如果不是用gearman的话,需要的时间为N*t,平均等待时间为N*t/2。
如果使用了gearman的话,并且N<=M,需要的时间为t,平均等待时间为t;如果N>M的话,需要的时间为(N/M)*t or (N/M+1)*t。
4. 异步方式的话,任务交给后端Worker后,前端Client就返回了,这样用户体验比较好。但是,存在任务执行失败或者是任务结果反馈的问题。
一般采用数据库作为存储,将任务执行的状态信息、结果等存入数据库;前端Client定期检查数据库中的结果,再进一步进行操作,是向用户呈现结果还是重新执行任务。
总体来看,gearman适合于那种task数量远远大于worker数量的应用。理论上来看,将计算开销转移到Worker上,从而实现任务的并发执行,表现为client计算负载减轻,用户的等待时间减少。
—————————–其他结构图分享————————————–
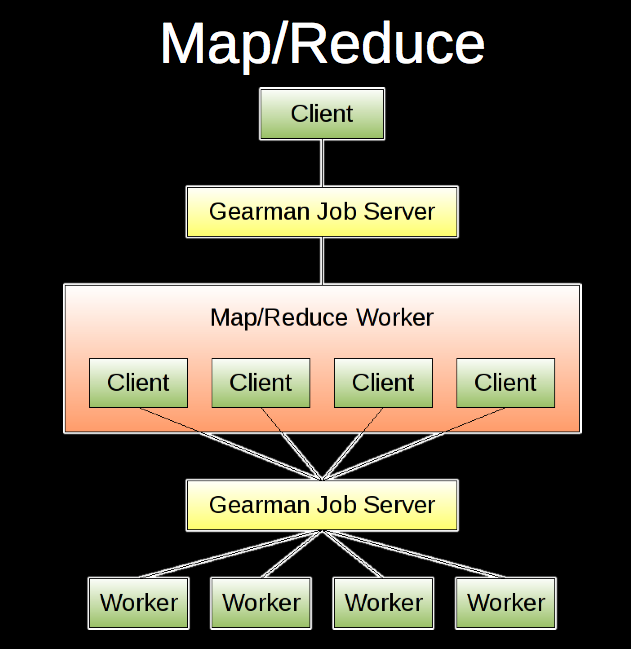
Map/Reduce构架图
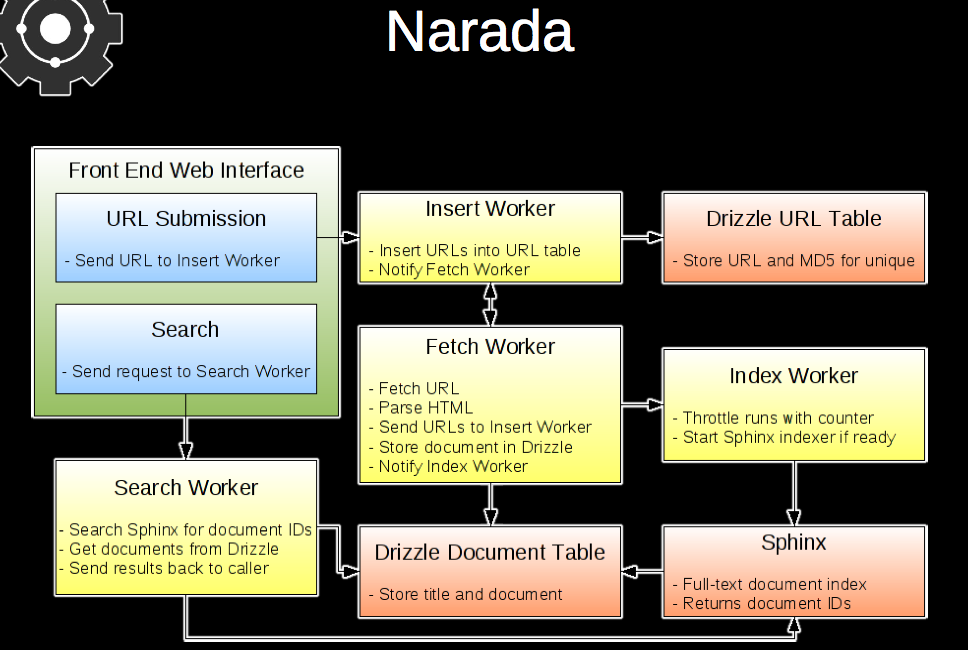
Narada开源搜索架构图
日志聚集和检索日志处理
