PS:描述
-
摘要
本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题。特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BTree索引,哈希索引,全文索引等等。为了避免混乱,本文将只关注于BTree索引,因为这是平常使用MySQL时主要打交道的索引,至于哈希索引和全文索引本文暂不讨论。
文章主要内容分为三个部分- 第一部分主要从数据结构及算法理论层面讨论MySQL数据库索引的数理基础。
- 第二部分结合MySQL数据库中MyISAM和InnoDB数据存储引擎中索引的架构实现讨论聚集索引、非聚集索引及覆盖索引等话题。
- 第三部分根据上面的理论基础,讨论MySQL中高性能使用索引的策略。
-
数据结构及算法基础
-
索引的本质
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。提取句子主干,就可以得到索引的本质:索引是数据结构。
我们知道,数据库查询是数据库的最主要功能之一。我们都希望查询数据的速度能尽可能的快,因此数据库系统的设计者会从查询算法的角度进行优化。最基本的查询算法当然是顺序查找(linear search),这种复杂度为O(n)的算法在数据量很大时显然是糟糕的,好在计算机科学的发展提供了很多更优秀的查找算法,例如二分查找(binary search)、二叉树查找(binary tree search)等。如果稍微分析一下会发现,每种查找算法都只能应用于特定的数据结构之上,例如二分查找要求被检索数据有序,而二叉树查找只能应用于二叉查找树上,但是数据本身的组织结构不可能完全满足各种数据结构(例如,理论上不可能同时将两列都按顺序进行组织),所以,在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
看一个例子:
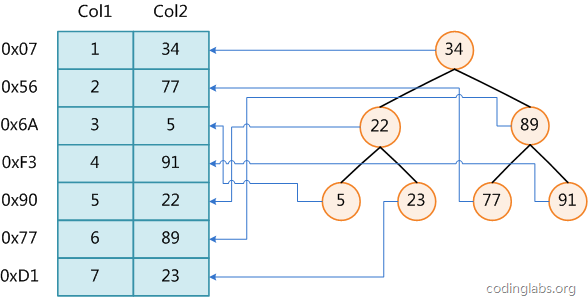
图1
图1展示了一种可能的索引方式。左边是数据表,一共有两列七条记录,最左边的是数据记录的物理地址(注意逻辑上相邻的记录在磁盘上也并不是一定物理相邻的)。为了加快Col2的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据记录物理地址的指针,这样就可以运用二叉查找在
的复杂度内获取到相应数据。虽然这是一个货真价实的索引,但是实际的数据库系统几乎没有使用二叉查找树或其进化品种红黑树(red-black tree)实现的,原因会在下文介绍。
-
B-Tree和B+Tree
目前大部分数据库系统及文件系统都采用B-Tree或其变种B+Tree作为索引结构,在本文的下一节会结合存储器原理及计算机存取原理讨论为什么B-Tree和B+Tree在被如此广泛用于索引,这一节先单纯从数据结构角度描述它们。
-
B-Tree
为了描述B-Tree,首先定义一条数据记录为一个二元组[key, data],key为记录的键值,对于不同数据记录,key是互不相同的;data为数据记录除key外的数据。那么B-Tree是满足下列条件的数据结构:
d为大于1的一个正整数,称为B-Tree的度。
h为一个正整数,称为B-Tree的高度。
每个非叶子节点由n-1个key和n个指针组成,其中d<=n<=2d。
每个叶子节点最少包含一个key和两个指针,最多包含2d-1个key和2d个指针,叶节点的指针均为null 。
所有叶节点具有相同的深度,等于树高h。
key和指针互相间隔,节点两端是指针。
一个节点中的key从左到右非递减排列。
所有节点组成树结构。
每个指针要么为null,要么指向另外一个节点。
-
-
-
大标题
-
大标题
大标题描述
-
二级标题
-
参考:
1.原文